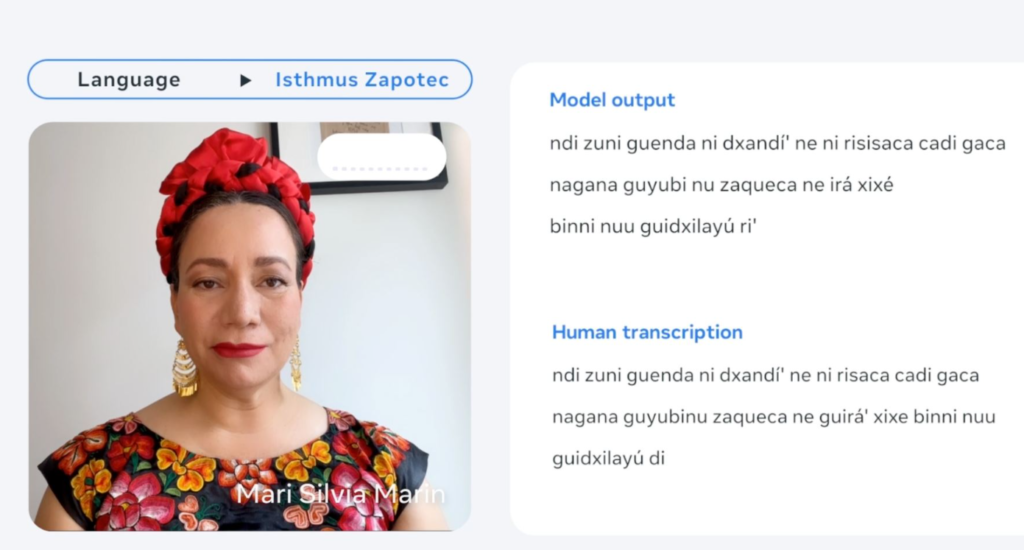
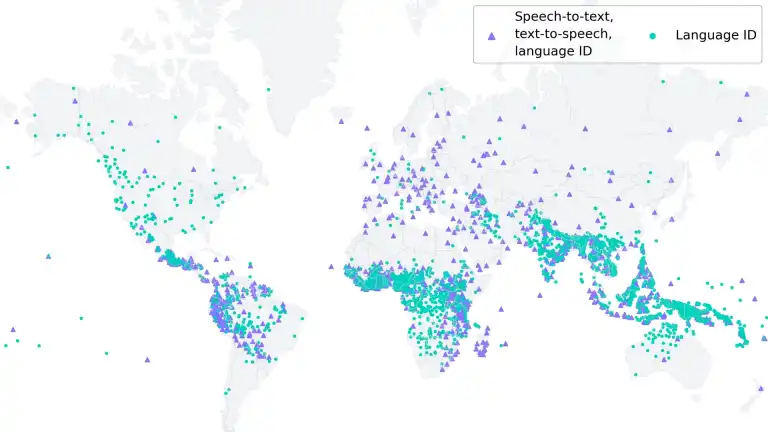
Meta anunció nuevos modelos de IA capaces de reconocer y reproducir el habla en más de 1100 idiomas. Tiene diez veces la capacidad de tecnologías similares existentes, dijo la compañía en un comunicado. Enfatizó que esta es una iniciativa para preservar lenguas que están en riesgo de desaparecer.
Este Massively Multilingual Speech (MMS) está disponible para el público a través del servicio de alojamiento de código GitHub. Meta explicó que liberarlos como código abierto ayudará a los desarrolladores a crear nuevas aplicaciones de voz más inclusivas.
El nuevo modelo puede leer texto en más de 1100 dialectos y convertirlo en voz (y reconocer el habla y convertirlo en texto). Sin embargo, podrían identificar más de 4.000, lo que representaría 40 veces la capacidad disponible actualmente.
Hay alrededor de 7,000 idiomas en el mundo, pero las herramientas de reconocimiento de voz convencionales existentes solo pueden reconocer alrededor de 100. La mayoría de estos sistemas suelen requerir grandes cantidades de datos de entrenamiento etiquetados, como transcripciones. El problema es que estos también solo están disponibles en un puñado de idiomas, incluidos español, inglés y chino.
Meta aprovecho un modelo de inteligencia artificial creado en el 2020
Meta aprovecha un modelo de inteligencia artificial que desarrolló en 2020. El sistema ya puede aprender patrones de voz a partir de audio sin necesidad de grandes cantidades de datos etiquetados, como transcripciones.
La empresa matriz de Facebook e Instagram, utilizó dos nuevos conjuntos de datos. Las primeras grabaciones de audio y textos del Nuevo Testamento de la Biblia, disponibles en Internet en 1.107 idiomas. MIT Technology Review publicó una segunda grabación sin etiquetar del Nuevo Testamento, que contiene 3.809 dialectos.
Los investigadores de Meta utilizaron un algoritmo diseñado para alinear las grabaciones con el texto que las acompaña. Luego repitieron el mismo proceso con un segundo algoritmo, entrenando con los datos recién alineados. Al final, el equipo logró entrenar el algoritmo para aprender un nuevo idioma más fácilmente, incluso sin el texto que lo acompaña.
Meta comparó su modelo con los de OpenAI Whisper y otros competidores. Dijo que su tasa de error era la mitad, a pesar de cubrir 11 veces más idiomas.
“Ahora podemos construir sistemas de voz muy rápidamente con muy, muy pocos datos”, dijo al MIT Michael Auli, científico del proyecto. Sin embargo, los investigadores advierten que estos modelos de lenguaje impulsados por IA aún pueden transcribir ciertas palabras o frases incorrectamente. De hecho, esto puede conducir a un etiquetado inexacto o potencialmente ofensivo.
Amazon quiere eliminar los códigos de barras y está utilizando inteligencia artificial para lograrlo. La empresa ha desarrollado un modelo de IA que utiliza cámaras para identificar productos, por lo que ya no es necesario escanear códigos de barras. Según el gigante del comercio electrónico, el sistema simplificará el procesamiento de envíos en los centros logísticos, lo que resultará en tiempos de entrega más cortos.
Si bien los códigos de barras están en el corazón del proceso de envío de Amazon, la empresa quiere eliminar su dependencia de ellos. Hay varias razones para esto, pero la razón principal es la automatización. El escaneo de productos requiere un empleado porque los robots no son lo suficientemente versátiles para manejar y ejecutar productos.
Cuando un artículo llega a un centro logístico de Amazon, los empleados usan códigos de barras para verificar su identidad en varios puntos a lo largo del viaje del vehículo de entrega. Cada vez, se debe recoger el artículo y colocar y escanear el código de barras. A veces, los códigos de barras se dañan o incluso se pierden.
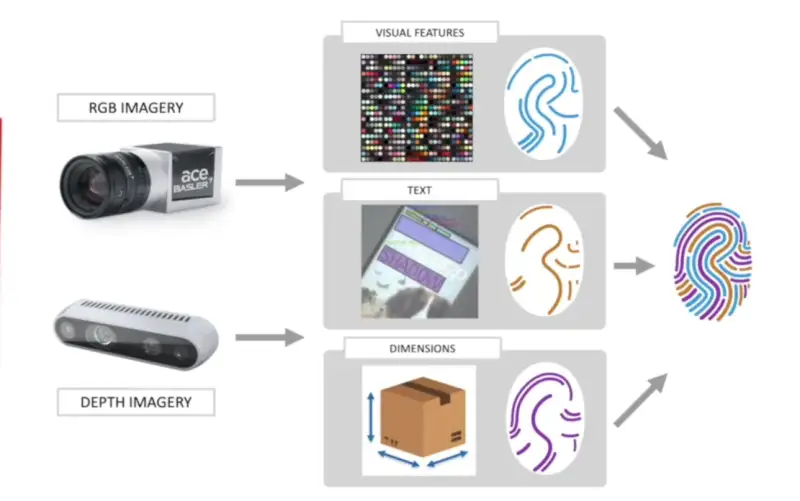
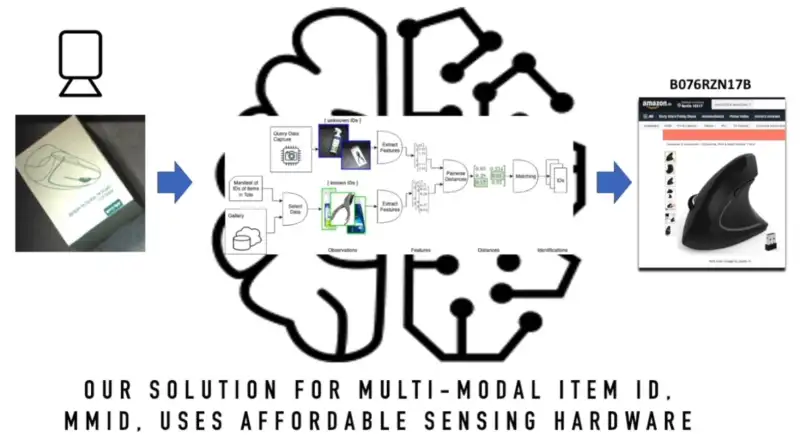
Para modernizar sus almacenes, Amazon compartió detalles de un proceso llamado Identificación multimodo. El primer paso para eliminar su dependencia de los códigos de barras es tomar fotografías de los productos a medida que se mueven a lo largo de la cinta transportadora. Los modelos de IA toman valores como el tamaño, las características visuales, el texto del empaque o el peso.
Amazon empleara IA para identificar cada paquete
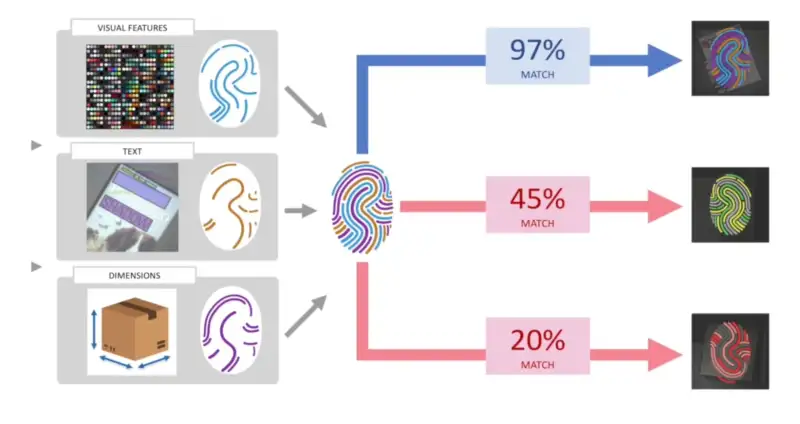
Con la ayuda de cámaras y cámaras de profundidad, se crea una especie de huella digital para cada objeto. Luego, los investigadores convirtieron los datos de cada imagen en vectores y construyeron un modelo de aprendizaje automático para extraer los datos y asociarlos con los productos a comparar.
Según Amazon, la tasa de coincidencia del algoritmo osciló entre el 75 % y el 80 % la primera vez que se usaron. A medida que se capturaban continuamente nuevas imágenes para entrenar el modelo de IA, MMID logró una precisión del 99 por ciento. Según el ingeniero, la alta tasa de coincidencia también se debe a que el sistema de inventario de la empresa sabe dónde se encuentra cada artículo, por lo que el algoritmo no necesita hacer coincidir el producto con todo el catálogo de la empresa.
El sistema está diseñado para no ser intrusivo, lo que permite la detección temprana de errores. Los palets individuales forman parte de las etapas iniciales del proceso, por lo que si existen discrepancias no es necesario esperar hasta el final para resolverlas.
Las fotos tomadas por la cámara se envían a la base de datos y entrenan el algoritmo. La iluminación y la velocidad en la cinta transportadora también son importantes, y Amazon se asegura de verificarlas. El único inconveniente se presenta cuando los empleados manipulan objetos en la bandeja, ya que esto puede dificultar la detección dependiendo de cómo sostengan el artículo.
Los ingenieros de Amazon ahora están trabajando para integrarlo con un brazo robótico para que en el futuro no se requiera la presencia humana. La empresa confía en que puede eliminar su dependencia de la identificación manual de artículos, un proceso tedioso e ineficiente.