



Meta anunció nuevos modelos de IA capaces de reconocer y reproducir el habla en más de 1100 idiomas. Tiene diez veces la capacidad de tecnologías similares existentes, dijo la compañía en un comunicado. Enfatizó que esta es una iniciativa para preservar lenguas que están en riesgo de desaparecer.
Este Massively Multilingual Speech (MMS) está disponible para el público a través del servicio de alojamiento de código GitHub. Meta explicó que liberarlos como código abierto ayudará a los desarrolladores a crear nuevas aplicaciones de voz más inclusivas.
El nuevo modelo puede leer texto en más de 1100 dialectos y convertirlo en voz (y reconocer el habla y convertirlo en texto). Sin embargo, podrían identificar más de 4.000, lo que representaría 40 veces la capacidad disponible actualmente.
Hay alrededor de 7,000 idiomas en el mundo, pero las herramientas de reconocimiento de voz convencionales existentes solo pueden reconocer alrededor de 100. La mayoría de estos sistemas suelen requerir grandes cantidades de datos de entrenamiento etiquetados, como transcripciones. El problema es que estos también solo están disponibles en un puñado de idiomas, incluidos español, inglés y chino.
Meta aprovecho un modelo de inteligencia artificial creado en el 2020
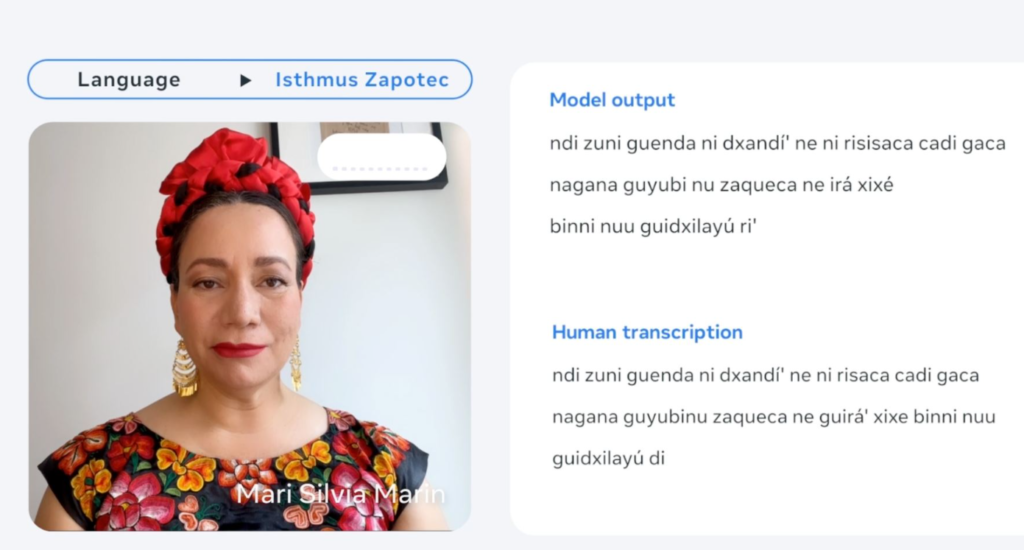
Meta aprovecha un modelo de inteligencia artificial que desarrolló en 2020. El sistema ya puede aprender patrones de voz a partir de audio sin necesidad de grandes cantidades de datos etiquetados, como transcripciones.
La empresa matriz de Facebook e Instagram, utilizó dos nuevos conjuntos de datos. Las primeras grabaciones de audio y textos del Nuevo Testamento de la Biblia, disponibles en Internet en 1.107 idiomas. MIT Technology Review publicó una segunda grabación sin etiquetar del Nuevo Testamento, que contiene 3.809 dialectos.
Los investigadores de Meta utilizaron un algoritmo diseñado para alinear las grabaciones con el texto que las acompaña. Luego repitieron el mismo proceso con un segundo algoritmo, entrenando con los datos recién alineados. Al final, el equipo logró entrenar el algoritmo para aprender un nuevo idioma más fácilmente, incluso sin el texto que lo acompaña.
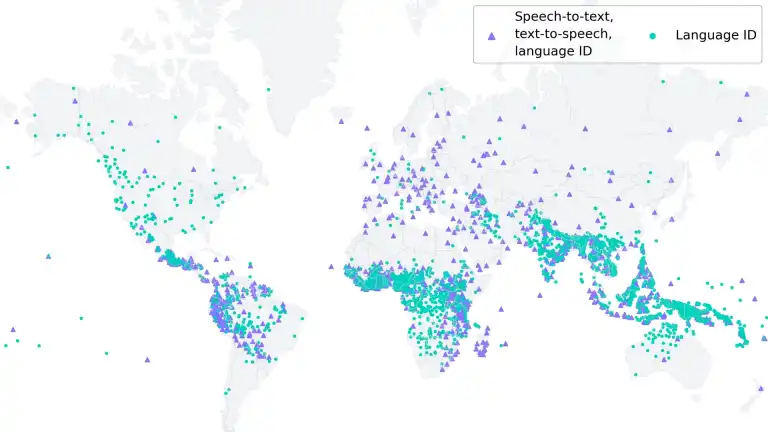
Meta comparó su modelo con los de OpenAI Whisper y otros competidores. Dijo que su tasa de error era la mitad, a pesar de cubrir 11 veces más idiomas.
“Ahora podemos construir sistemas de voz muy rápidamente con muy, muy pocos datos”, dijo al MIT Michael Auli, científico del proyecto. Sin embargo, los investigadores advierten que estos modelos de lenguaje impulsados por IA aún pueden transcribir ciertas palabras o frases incorrectamente. De hecho, esto puede conducir a un etiquetado inexacto o potencialmente ofensivo.
También te puede interesar: OpenAI lanza una App de ChatGPT exclusiva para usuarios de iOS









